抓取网页ext-930x620.jpg)
如何定期(自动)抓取网页
网页抓取是以结构化格式从网页中提取数据的过程。这是从在线站点获取数据的最有效方法之一——尤其是当您需要将数据输入应用程序或其他网站时。
网络抓取——也称为数据抓取——有很多应用,包括比较多个网站的价格、收集市场研究数据、产品监控、研究等。作为一名数据科学家,我发现它对于获取使用 API 无法获得的数据最有用. 作为初学者或专业用户,您可能会发现它对于比较价格或从 Web 收集数据很有用。
在本文中,我将向您介绍两种网页抓取方法。第一种方法是一种对初学者友好的方法,可以使用现成的解决方案来抓取数据。第二种方法是使用 Scrapy 对程序员友好的方式来抓取数据,如果做得好,它支持强大的抓取。让我们检查一下。
方法#1:使用抓取工具
如果您不是开发人员或不熟悉 Python,这里有一个简单的解决方案。市场上有许多用于抓取网络的工具,允许您通过零到一些编程来抓取网络。令人惊讶的是,一些网络抓取工具允许您通过其直观的界面抓取网络。
Octoparse 就是这样一个网页抓取工具,它可以让你轻松地抓取网页。正如我将在本文后面详细介绍的那样,Octoparse 允许您通过三个简单的步骤执行抓取。幸运的是,它确实通过其应用程序提供了一个在本地抓取数据的免费计划,允许您以零投资执行小型抓取任务。
此外,Octoparse 具有许多高级功能,无需编程即可动手进行网页抓取。我发现它的模板很有趣,因为它们允许您无需配置即可从热门网站抓取数据。例如,您可以选择一个预建模板来从 Amazon 或 eBay 抓取产品数据。
使用自动数据提取
Octoparse 功能强大且方便。原因是它支持自发地从网页中检测和提取数据。虽然我发现它主要适用于数据列表或表格,但它是最快的入门方式。就是这样:
- 转到https://www.octoparse.com/signup并注册一个免费帐户。
- 确认您的电子邮件地址并登录 Octoparse 后,您将看到一个屏幕,上面写着“帐户已准备就绪!” > 单击开始免费高级试用。
- 输入您的银行卡详细信息或使用 PayPal 结帐以激活试用。
- 单击下载我们的免费软件以下载适用于您的平台(Windows 或 macOS)的应用程序。然后,单击8.1 Beta按钮。
- 解压缩下载的 zip 存档并打开Octoparse Setup 8.1.xx.exe以安装其应用程序。然后,按照屏幕上的说明进行操作。
- 安装后,打开 Octoparse 并登录您的帐户。请记得勾选记住密码和自动登录选项。
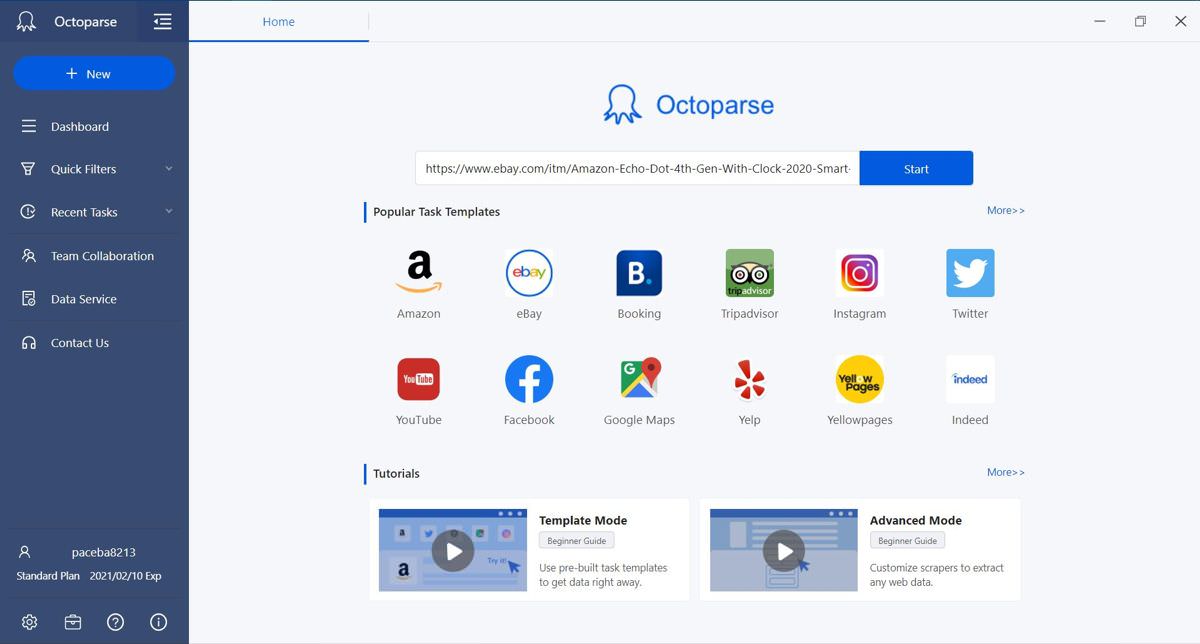
- 您将看到 Octoparse 的界面,您可以在其中查看视频教程。
- 在文本框中输入网址,然后按“开始”。例如,我要
https://www.ebay.com/itm/Amazon-Echo-Dot-4th-Gen-With-Clock-2020-Smart-Speaker-Alexa-All-Colors-NEW/363219888368在这里刮。 - Octoparse 将加载网页并尝试检测和提取潜在数据。在提示下,取消选中单击“加载更多”按钮选项。
- 如果应用程序下半部分显示的数据不是您要查找的数据,请单击“切换自动检测结果”以查看更多信息。
- 看到预期数据后,单击创建工作流按钮。
使用手动数据提取
有时,Octoparse 的自动数据提取功能可能无法满足您的需求。也许您尝试从中提取数据的网页很复杂或动态。不管是哪种情况,您都可以使用 Octoparse,因为它还允许手动选择要提取的数据。方法如下:
- 按照“使用自动数据提取”下的步骤进行操作,直到第 8 步。
- Octoparse 将开始加载网页并检测要提取的潜在数据。在提示下,单击取消自动检测以手动提取数据。
- 现在单击网页上的数据项以提取这些数据。例如,我点击了 Echo Dot 4th Gen 的标题、价格和运费。
- 在“提示”对话框中,单击“提取数据”选项以测试工作流。
- 最后,单击Octoparse 左上角附近的保存以保存它。
后置条件
好的,我们已经创建了通过 Octoparse 从 eBay 提取定价信息的任务。但是,它还不是自动化的。也就是说,您现在必须手动运行它。也就是说,让我们检查一下如何自动化它以定期提取数据:
- 在您的任务选项卡中,单击Octoparse 左上角附近的运行。
- 单击运行任务对话框中的计划任务(云)按钮。
- 单击一次、每周、每月和重复之一,然后对其进行配置。
- 最后,单击“保存”或“保存并运行”按钮之一进行保存。
最后,它完成了。您的任务将根据您配置的时间表在 Octoparse Cloud 中自动运行。您可以通过单击Dashboard,单击任务的更多按钮,然后选择View data > Cloud data来查看数据。
方法#2:使用自定义程序
如果您已经查看了第一种方法并想要更多控制,或者您是一名程序员并且想学习以编程方式抓取网页,则必须尝试这种方法。我们将利用 Scrapy 来构建解决方案。我假设您具有使用 HTML & CSS 和 Python 的实践知识。
Scrapy 是一个用于从网站提取数据的开源框架。它是数据科学家中流行的数据抓取工具。根据我的经验,它适用于小型或大型项目,但您可能需要正确配置它并实施第三方工具才能使其对大型抓取项目有效。
先决条件
你知道 CSS 中的选择器吗?在任何网页上,选择器都有助于识别和选择特定元素。您可以在 W3Schools 上阅读有关选择器的信息。例如,如果要查找网页上的所有热门标题,可以使用 h1as 选择器。以下是在Google Chrome中查找元素选择器的方法:
- 右键单击页面上的元素 > 选择Inspect。例如,我试图在下面找到文本“Example Domain”的选择器。
- 右键单击 Elements 下的元素,转到Copy > Copy selector。
使用废料
如果您正在尝试抓取本文未讨论的任何网页,或者您想抓取这些页面中的更多数据,则需要找到选择器并使用它们。也就是说,让我们开始吧。在下面的示例中,我将使用 Scrapy 从 eBay 上抓取 Amazon Echo Dot 4th Gen 的价格。让我们开始吧:
- 为你的项目创建一个新文件夹,说“scrape-web-regularly”。
- 打开一个终端,切换到这个文件夹(即
cd scrape-web-regularly),然后运行以下命令来安装 Scrapy:pip install scrapy。 - 在此文件夹中创建一个新文件(“try-one.py”)并在代码编辑器中打开它。将以下代码复制到此文件中,根据需要进行更改,然后保存。
- 在终端中,运行以下命令:
scrapy runspider try-one.py执行抓取。如果您正在为其他网页/网站写作,有时您可以尝试运行它以获得正确的选择器。 - 如果您使用与我完全相同的代码或在您的自定义代码中使用了正确的选择器,您将获得类似于示例输出的输出:
- 如果您的代码与我的不同或者您使用了错误的选择器,您将看不到包含
DEBUG: Scraped from. 否则,您会看到一条消息,其中包含{'title'— 这是抓取的数据。
如果出现错误,请仔细阅读消息以找到缓解步骤。例如,如果错误显示“错误:需要 Microsoft Visual C++ 14.0 或更高版本。使用 Microsoft C++ Build Tools 获取它:https://visualstudio.microsoft.com/visual-cpp-build-tools/ “,您应该从给定的链接下载并安装它,然后重试。在这种情况下,您可以选择使用Anaconda下载预构建的包。
|
1个
2个
3个
4个
5个
6个
7
8个
9
10
11
12
13
14
15
16
17
|
import scrapyclass EBaySpider(scrapy.Spider): # name of the scraper name = 'ebay_spider' # link or URL to scrape from link1 = 'https://www.ebay.com/itm/Amazon-Echo-Dot-4th-Gen-With-Clock-2020-Smart-Speaker-Alexa-All-Colors-NEW/363219888368' # links or URLs to scrape data from start_urls = [link1] def parse(self, response, **kwargs): # select the element to scrape data from for title in response.css('#prcIum'): # extract the text data from element yield {'price': title.css('::text').get()} |
|
1个
2个
3个
4个
5个
6个
7
8个
9
|
[scrapy.core.engine] INFO: Spider opened[scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)[scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023[scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.ebay.com/itm/Amazon-Echo-Dot-4th-Gen-With-Clock-2020-Smart-Speaker-Alexa-All-Colors-NEW/363219888368> (referer: None)[scrapy.core.scraper] DEBUG: Scraped from <200 https://www.ebay.com/itm/Amazon-Echo-Dot-4th-Gen-With-Clock-2020-Smart-Speaker-Alexa-All-Colors-NEW/363219888368>{'price': 'US $59.99'}[scrapy.core.engine] INFO: Closing spider (finished) |
但是,如果您没有看到任何这些消息,请检查输出是否包含 DEBUG: Crawled (200). 如果不是,则 Scrapy 无法抓取或获取网页。可能有多种原因,因此有多种故障排除提示:
- 首先,检查您的互联网连接是否正常。
link1如果是,请检查您是否可以在网络浏览器中打开编码。link1如果不是,则为错误链接:更改代码中的值。- 如果还没有成功,可能有多种原因;让我们来看看它们:
- 如果您至少能够获得一次数据或响应,则可能是您在短时间内抓取或抓取页面的次数过多,导致网站阻止了您的请求。在这种情况下,您可以增加连续抓取或运行之间的间隔。
- 如果不是,目标网站可能使用了一些抓取保护技术,阻止了您使用 Scrapy 抓取页面的请求。在这种情况下,请检查下一节。
使用 ScrapingBee
ScrapingBee 是一种网络抓取服务,用于绕过抓取保护技术并在不被阻止的情况下抓取网络。它提供了一个简单的 API,用于使用无头浏览器和旋转代理来抓取网络,让您在使用 Scrapy 抓取时绕过抓取保护技术。
例如,我开始尝试使用 eBay 进行抓取,但没有成功。eBay 检测并阻止所有请求,直到它们来自使用真实网络浏览器的真实用户,因此,Scrapy 不适用于 eBay。此外,您可能会发现大型或流行的网站使用 Scrapy 处理某些请求,但随后,它们也开始阻止这些请求。这就是 ScrapingBee 非常方便的地方。
我喜欢 ScrapingBee 提供的免费试用版,其中包括对其 API 的 1,000 次免费调用,允许您测试其服务和/或在小型抓取项目上工作。也就是说,让我们开始在我们的 Scrapy 项目中使用 ScrapingBee API:
- 前往https://www.scrapingbee.com/并点击Sign Up进行注册。
- 确认您的电子邮件地址并登录 ScrapingBee 后,您将看到其仪表板提供您的帐户信息等。
- 在Request Builder下,在URL下输入您要抓取的链接。如果页面不需要 JavaScript,请取消选中JavaScript Rendering。我正试图从 eBay 上抢购 Amazon Echo Dot 4th Gen 的价格。
- 在cURL选项卡下,复制引号之间的链接(同时跳过“curl”字样)并将值粘贴到
link1代码中。于是,link1 = 'https://www.ebay...就变成了link1 = 'https://app.scrap...。 - 现在,从上面使用 Scrapy部分下的步骤 #4 继续。
后置条件
您已经完成了抓取器的构建,即抓取数据的逻辑。但它不会定期运行,而是需要您自己手动运行它,这不是本教程的目标。因此,让我们尝试自动化我们的自定义抓取工具,以便它以预定的时间间隔自动运行。
在 Ubuntu 和 Linux Mint 等 Linux 操作系统中,您可以使用 cron 作业定期运行您的爬虫。您可以阅读此cron 指南,然后按照以下步骤操作:
- 打开终端并运行
crontab -e以编辑用户的 cron 文件。 - 输入
<CRON_SCHEDULE> cd <PROJECT_DIR> scrapy runspider try-one.pycron 文件并保存以安排您的 cron 作业。 - CRON_SCHEDULE:默认计划是
* * * * *每分钟运行一次。或者0 * * * *这意味着每小时运行一次,或者0 0 * * *这意味着每天运行一次。 - PROJECT_DIR:您创建 Scrapy 项目的目录。检查上面使用 Scrapy部分下的步骤 #1 。
现在,您的爬虫将在 Linux 操作系统中使用 cron 在预定时间定期运行。如果您使用的是 Windows 10,则可以使用任务计划程序安排您的抓取任务定期运行。阅读我的自动化重复性任务指南。
这就是使用像 Octoparse 这样的现成平台和使用 Scrapy 和 ScrapingBee 的定制程序来抓取网站。