我听说 RAID 1+0 比 RAID 0+1 更易于发生故障,因为辅助驱动器故障比 RAID 1+0 更容易导致 RAID 0+1 中的数据丢失。
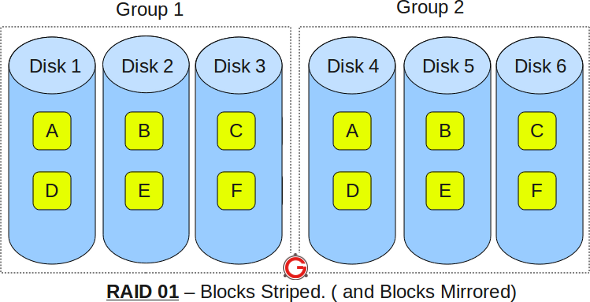
在上图中,如果“磁盘 1”发生故障,其他哪些磁盘故障会导致数据丢失?我读到的内容似乎表明“组 2”中任何驱动器的丢失都会导致数据丢失,但我不清楚这背后的原因。如果我们丢失了“磁盘 5”,为什么会导致数据丢失?在我看来,有足够的信息来恢复完整的数据状态 – 例如,将“磁盘 4”+“磁盘 2”+“磁盘 3”组合起来,应该具有继续正常运行而不会丢失数据所需的所有信息。
那么为什么“磁盘1”和“磁盘5”丢失会导致数据丢失呢?
提前致谢!
3
最佳答案
1
这取决于 RAID 层的实施细节。
例如,如果您使用硬件 RAID 进行条带化,然后使用软件 RAID 来镜像条带组,那么执行镜像的软件 RAID 将看不到单个磁盘,而只能看到代表每个条带组的硬件 RAID 生成的两个设备。
在这样的配置中,当磁盘 1 发生故障时,硬件 RAID 控制器将在组 1 设备上返回错误。然后,顶层的软件 RAID 必须将整个组 1视为发生故障,因为它看不到单个磁盘。
如果磁盘 5 随后发生故障,则第 2 组设备也将开始返回错误,对于执行镜像的软件 RAID 而言,这是双重故障 – 数据丢失。游戏结束。
如果您尝试使用磁盘 4、2 和 3 进行恢复,则会出现这样的问题:磁盘 1 发生故障后,软件 RAID 将停止更新整个组 1。因此,除非两个磁盘同时发生故障,否则磁盘 4 的数据将比磁盘 2 和 3 的数据更新……这种情况不太可能发生。而且由于条带化,任何长度超过一个条带的连续数据都有可能同时合并“较旧”和“较新”条带集的部分数据,从而导致损坏混乱。
如果条带化和镜像都由同一个RAID 实现完成,即,要么只是一个可以执行“RAID 10”或“RAID 0+1”的硬件 RAID 控制器,要么只是一个可以执行相同操作的软件 RAID 实现,那么该实现可能足够智能,可以在磁盘 1 发生故障后继续更新磁盘 2 和 3,即使第 1 组条带集不再完整。如果磁盘 5 也发生故障,控制器可能足够智能,能够看到磁盘 4 + 2 + 3 一起形成一个有效集,并继续运行。
每当相同的 RAID 实现处理条带化和镜像时,现代实现通常会按照您想象的方式工作 – 它们跟踪每组条带的每个副本的健康状况,并且只要可以找到完整的条带集就会继续工作。
但是,这并不是您应该盲目信任的事情:您应该提前仔细研究您的 RAID 实现,以便当(而不是“如果”!)磁盘开始出现故障时,您就会知道您的 RAID 实现能做什么和不能做什么。
如果您将不同的 RAID 实现层叠在一起(例如,如果您使用操作系统的内置软件 RAID 在位于不同建筑物中的两个大型 SAN 存储系统之间镜像数据以实现容灾),那么您应该仔细考虑故障场景 –在设计阶段,甚至在开始实施设置之前。
2
-
还要注意,提到的设计阶段(粗体!)是你真正认真考虑系统要求的地方。例如,镜像将减慢写入所有镜像中最慢的镜像的速度。一旦你在旋转介质上进行随机访问,这一点就变得非常非常重要,因为如果有不能等待的寻道,寻道时间会变得非常随机,而且你会非常快地填充任何可以缓冲写入数据的东西。在这种情况下,条带化不会给你带来多大好处。另一方面,读取密集型用例可能没问题。
– -
您还需要考虑您真正要保护自己免受哪些故障模式的影响。我发现简单的镜像在没有奇偶校验/校验的情况下始终是不够的。太好了,您有两份相同的数据,现在一份出现了一点翻转。哪一个是对的?您似乎有足够的磁盘,这可能真的需要更复杂的 RAID 5 或 RAID 6 设置,或者您可以选择一些不那么经典的设置,例如 ZFS zRAID。但如果您只是要确保自己免受整个磁盘的彻底故障,那么镜像当然是好的。
–
|
–
–
–
|